[対象: 上級]
JavaScriptやCSSなどの外部リソースを取得してレンダリングする機能がFetch as Googleに追加されました。
この記事では、レンダリングを実行するGooglebotの動きに関する2つの事象を紹介します。
- AjaxのURLを取得できない
- Cookieを受け入れる
AjaxのURLを取得できない
Googleの推奨仕様に従った、“#!”を用いたAjaxのURLを新しいFetch as Googleでは取得できなくなってしまいました。
以前は取得可能でした。
現在は、元からある「取得」と新しい「レンダリングして取得」の両方ともが不可能です。
しかしGoogleのJohn Mueller(ジョン・ミューラー)がこのことをAaron Bradley(アーロン・ブラッドレー)氏によるGoogle+の投稿で知り、次のようにコメントしています。
修正してサポートしなければならないだろう。
しばらくの間は、自分で書き換えて送信してほしい。
具体的にいつとまでは言及していませんが、問題はGoogleに伝わっているのでいずれ今までのようにAjaxコンテンツもFetch as Googleで再び取得できるようになるでしょう。
それまでは、“#!”を“?_escaped_fragment_=”に置き換えたURLを送信して確認してほしいとのことです。
とはいえ、#を使った本来のAjax URLをGooglebotが正しく取得できているかを知りたいわけで、少し残念な状況になっています。
修正が完了するまで待つしかないですね。
Cookieを受け入れる
一方、こちらはレンダリング用のFetch as GoogleがCookieを受け入れるという興味深い発見です。
Tom Anthony(トム・アンソニー)氏が自作したスクリプトで検証した結果、GooglebotがCookieを受け入れていることを発見しました。
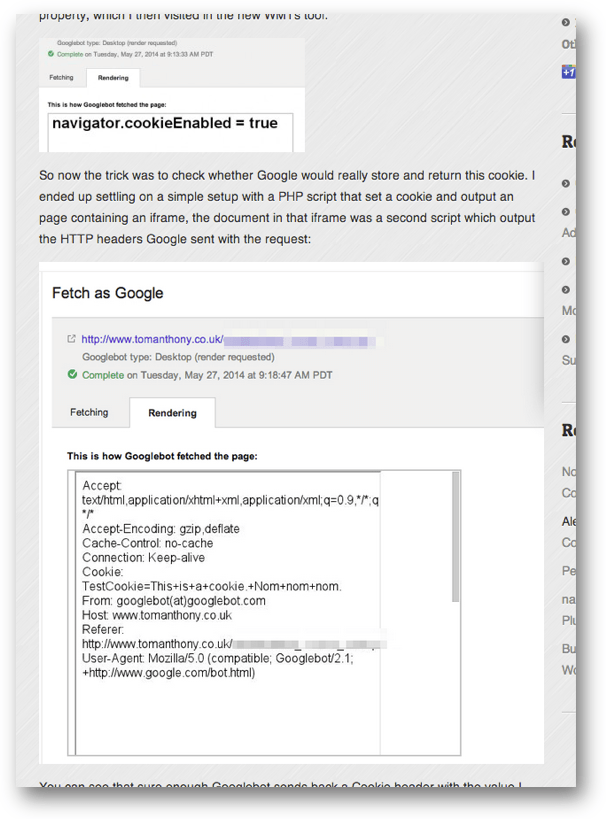
Cookieを受け入れて保存し、(リファラーとともに)サーバーに送り返すことを確認できたそうです。
もっとも、Fetch as Googleでレンダリング取得したときのGooglebotに限った話です。
通常のGooglebotがCookieを受け入れるようになったということではありません。
そうは言っても、GooglebotがCookieを処理することが技術的に可能になっているということですよね。
今までは発見できなかったコンテンツを、Cookieを扱えることで発見できるようになるかもしれません。
JavaScriptの理解力向上だけでなく、ここで見たCookie処理を含め、ウェブで使われるさまざまな仕組みにGoogleは次々と対応を進めているようです。