[対象: 上級]
Internet Archiveが提供するWayback Machineを使うとウェブページの過去の状態をアーカイブ(保存)できます。
新規に取得するドメイン名がスパムサイトでなかったかを確かめたり中古ドメインを悪用利用する際に以前に何をテーマにしたサイトだったかを調査したりと、そのサイトの過去の姿を知るときに重宝します。
Wayback Machineは現在、4,110億のウェブページをアーカイブしているとトップページに出ています(ちなみにGoogleがクロール/インデックスしたURLは60兆!)。

ところが自分が見たいURLがアーカイブされていないこともありえます。
独自のクローラでWayback Machineはウェブページを取得します。
しかし僕たち自身が手動でアーカイブさせることも可能だと知っていたでしょうか?(僕は知ったばかりです)。
Wayback Machineへのウェブページの保存方法
Wayback Machineにウェブページを保存する方法は簡単です。
トップページにある「Save Page Now」のボックスに保存したいウェブページのURLを入力して送信するだけです。

アーカイブが完了します。

リニューアル前のときの見た目がどうだったかを保存するために利用することもできそうですね。
自分でキャプチャして保存しておくよりも楽なんじゃないでしょうか。
ほかには、ベンチマークしているサイトの変化を記録するのにも使えそうです。
たとえばAmazonは絶えずデザインを変更しています。
ボタン1つにしても、これまでに何度もスタイルを変えています。
今は、流行りのフラットデザインになってますね。
Wayback Machineへのウェブページの保存を拒否する方法
「他人のサイトの過去は見たいけれど、自分のサイトの過去は見られたくない」という要望があるかもしれません。
Wayback Machineへのウェブページの保存を拒否する方法も併せて紹介しておきます。
robots.txtに以下を記述します。
User-agent: ia_archiver
Disallow: /
「ia_archiver」はWayback Machineのクローラの名前、つまりUser-Agentです。
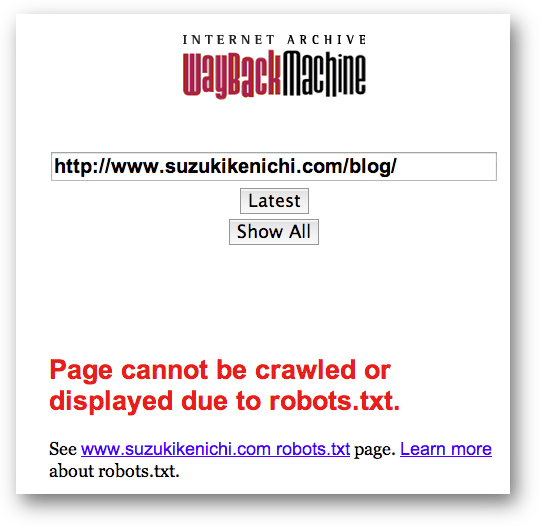
ia_archiverはきちんとrobots.txtの命令に従います。
僕のサイトはia_archiverのクロールをrobots.txtでブロックしているのでアーカイブを見られません。w
Internet ArchiveはWayback Machineを僕たちに無料で使わせてくれています。
もしあなたが頻繁に利用しているのであれば、感謝の気持を寄付で表しましょう。