[レベル:初級]
検索エンジンのクローラをブロックする必要がない時のrobots.txtの設定は、次の3つのうちどれが適切か?
- 何も書いていないrobots.txtを設置する
- 下の記述を書く
User-Agent: * Disallow:- robots.txtそのものを置かない
robots.txtについて、上の質問にGoogleのMatt Cutts(マット・カッツ)氏がビデオで回答しました。
1つ目か2つ目のどちらかが適切だろう。3つ目だと、ひょっとしたらほんの少しだけど危険かもしれない。
robots.txtを置いていないとサーバーのホスティング会社が404を埋めるために何かしてしまい、おかしな挙動を起こすことがあるからだ。
ほとんどの場合僕たちはうまく対処できるけど、1%といえど危険がないわけじゃない。だからブランクのrobots.txtを置くか、すべてのアクセスをクローラに許可しておくといい。どちらでもまったく変わらない。
同じようなことを繰り返しているので訳は端折ってますが、クローラを拒否しないのであれば空っぽのrobots.txtを置いておくか、何も拒否しない、つまりすべてを許可する記述を書いたrobots.txtを置いておくといいというアドバイスになります。
robots.txtを置かなくてもいいけれど、万が一の場合があるのでおすすめはしないとのことです。
robots.txtを置かない時は、robots.txtのリクエストがあった際(通常クローラはアクセスしたときに、最初にrobots.txtを探します。アクセスが禁止されているコンテンツがないか確認するためです)、404エラーまたは410エラーを返すようにします。
404/410を確実に返せば問題は発生しません。
でも例えば、500番台のエラーを返したりするとランキングが下がったり、ひどいときはインデックスから消えてしまうことがあります。
このあたりは、Web担当者Forumの連載で書いたこの記事とこの記事を参照してください。
僕がこれまで受けた問い合わせで、robots.txtが302(か301)でトップページにリダイレクトされていたり、サーバーのファイアーウォールの設定か何かでGooglebotだけがrobots.txtにアクセスできなかったりしたために、インデックスが消えたトラブルがありました。
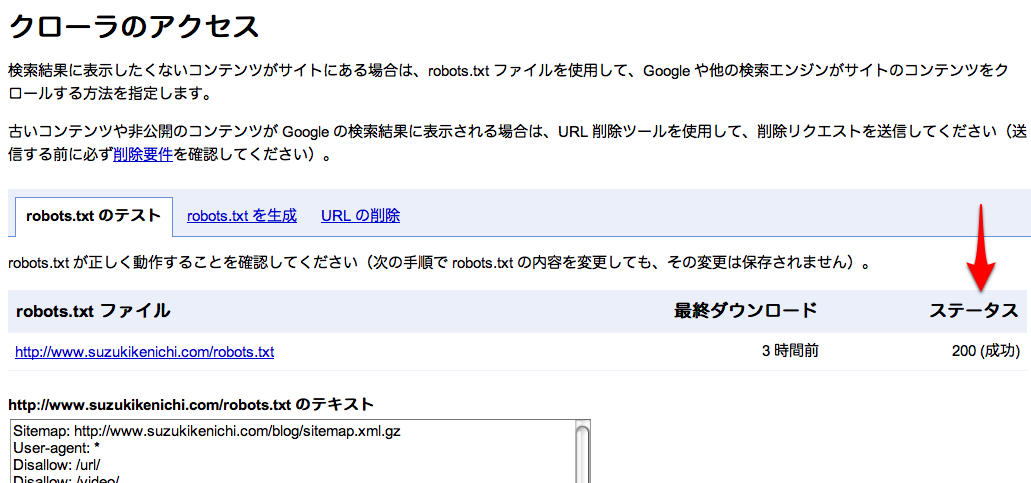
自分のサイトのrobots.txtにアクセスしてみて、設置している場合は200番のHTTPステータスコードが正しく返されているか、設置していない場合は404/410エラーが返されているかを確認しておきましょう。
Googleウェブマスターツールの「クローラのアクセス」で状態を確認できますね。
200が返されている時は、記述が正しく読み取られているかも併せて確認しておくといいでしょう。