[レベル: 初級]
robots.txt は、検索エンジンのクロールを拒否する仕組みであって、インデックスを拒否する仕組みではありません。
そうかと言って、インデックス拒否にまったく役立たないということでもありません。
robots.txt でブロックしたページでも検索結果に表示される
robots.txt でクロールをブロックしたページでも検索結果に出てくることがあります。
たとえば、Twitter カードのバリデーションを検証するツールのページは robots.txt でブロックされています。
にもかかわらず、検索結果には出てきます。
このツールを公開している cards-dev.twitter.com の robots.txt はサイト全体のクロールをブロックしています。
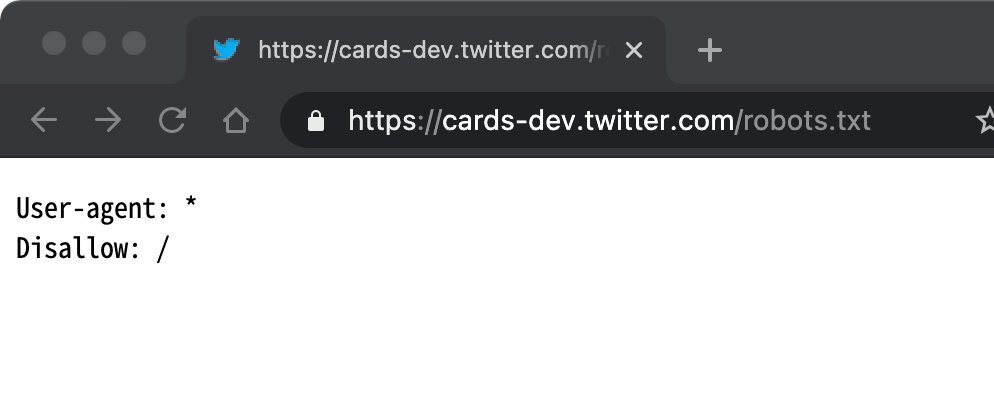
ただし、クロールしないためページの内容を検索エンジンは読み取ることができません。
meta description タグもページに書かれていることもわからないため、スニペットを作成できません。
「このページの情報はありません。」と書かれているだけで、関連するヘルプ記事へリンクしています。
また、ページタイトルが URL になる場合もあります。
クロールできず title タグを読み取れないからです(Twitter Card はリンク元のアンカーテキストを素にして検索結果のタイトルを判断していると思われる)。
robots.txt でブロックしていても検索結果に表示される可能性があることは Google の公式技術ドキュメントでも言及されています。
クローラをブロックしているページでも他のサイトからリンクされていればインデックス登録が可能
Google では、
robots.txtでブロックされているコンテンツをクロールしたりインデックスに登録したりすることはありませんが、ブロック対象の URL がウェブ上の他の場所からリンクされている場合、その URL を検出してインデックスに登録する可能性はあります。そのため、該当の URL アドレスや、場合によってはその他の公開情報(該当ページへのリンクのアンカー テキストなど)が、Google の検索結果に表示されることもあります。特定の URL が Google 検索結果に表示されるのを確実に防ぐには、サーバー上のファイルをパスワードで保護するか、noindexメタタグまたはレスポンス ヘッダーを使用する(もしくは該当ページを完全に削除する)必要があります。
検索結果の表示を確実に防ぐのであれば、一般的は noindex robots meta タグが推奨されます(ただし robots.txt と noindex の併用は無意味なので要注意)。
実質的には robots.txt でもインデックス防止に利用できる
では、インデックスの防止に robots.txt はまったく役立たないのかというとそういうことでもありません。
robots.txt がブロックした URL が検索結果に出てくるのは、たいていはそのページに多くのリンクが張られている場合です(ドキュメントにも書かれています)。
ほとんどリンクされていなければ ブロックしたページが検索結果に出てくることはそれほど頻繁ではないはずです(リンクがなければ、絶対に出てくるということではない)。
また、robots.txt でブロックしたペーを Google が検索結果に出すのは、クエリに対して関連性が高いページをほかに見つけられない場合です。
クロールしないため、ページの内容を Google は理解できません。
それでも、(アンカーテキストなど)そのほかの情報を頼りにして、クエリに対して最も関連性が高いと判断することがあります。
とはいえ、robots.txt でブロックしたページが上位表示するクエリは稀なはずです。
繰り返しになりますが、ページの内容を Google は知りません。
したがって、関連性を判断するシグナルは極めて限られます。
多くのクエリにおいて、中身がわからないページを上位表示はできないでしょう。
ということで、技術的には robots.txt はインデックス、言い換えれば検索結果の掲載を抑制しません。
しかし実質的には、インデックス・検索結果掲載の抑制にまったく使えないわけではないのです。
もちろん、インデックスを確実に防ぐのであれば robots.txt ではなく、noindex を構成します。
それでも、ほかに方法がないときの手段として robots.txt を完全に排除する必要はありません。
[H/T] Christian Oliveira, Vannesa Fox and John Mueller
One of the biggest #SEO misconceptions I keep seeing every week in the community is that robots.txt can be used to avoid Google to *index* certain URLs, which is false. Robots.txt only prevents Googlebot from *crawling*, not from indexing. Here is a basic example: pic.twitter.com/brFKyZA1sG
— Christian Oliveira (@christian_wilde) March 9, 2021
True, but the next misconception for those who hear that robots doesn't prevent indexing is that noindex attributes should be used instead when the reality is that URLs blocked with robots don't rank unless there are no other good results for the query (like your example).
— Vanessa Fox (@vanessafox) March 9, 2021
Yeah, the difference between technically indexed, and practically indexed is tricky.
— 🍌 John 🍌 (@JohnMu) March 9, 2021
Indexed & practically seen in normal search results vs not seen. It comes up often with old / removed content, site-moves, robotted URLs, etc. Technically it might be indexed, but is it worth the time to fix something nobody sees & which doesn't cause issues?
— 🍌 John 🍌 (@JohnMu) March 9, 2021