[レベル: 上級]
この記事では、3月に独ミュンヘンで開催されたSMX Munich 2016で参加したセッションをレポートします。
John Mueller(ジョン・ミューラー)氏とMariya Moeva(マリヤ・モエヴァ)氏の2人のGoogle社員から聞いた情報については、参加後にすぐに記事にしたものの、それ以外のセッションは紹介していませんでした。
1か月半ほど時間が空いてしまいましたが、その情報価値はまったく古くなっていないので安心して読んでください。
まずは、MozのRand Fishkin(ランド・フィッシュキン)氏による基調講演です。
フィッシュキン氏は、人工知能と機械学習によるGoogleのアルゴリズムの変化と、それにどう対応していくべきかについて語りました。

2012年の昔に戻ってみると
2012年の昔に戻ってみると、キーワードとコンテンツ、リンクそしてクロール可能なサイトが上位表示できた。たとえユーザー体験がすばらしくなかったとしても、リンクで競合に勝っていれば上位表示を維持できた。
Facebookでは、フォロワーのフィードにあなたのニュースがどのくらい頻繁に表示されるかは「いいね!」とシェアで決まった。Twitterでは、投稿にかける時間で露出度が完全に決まった。
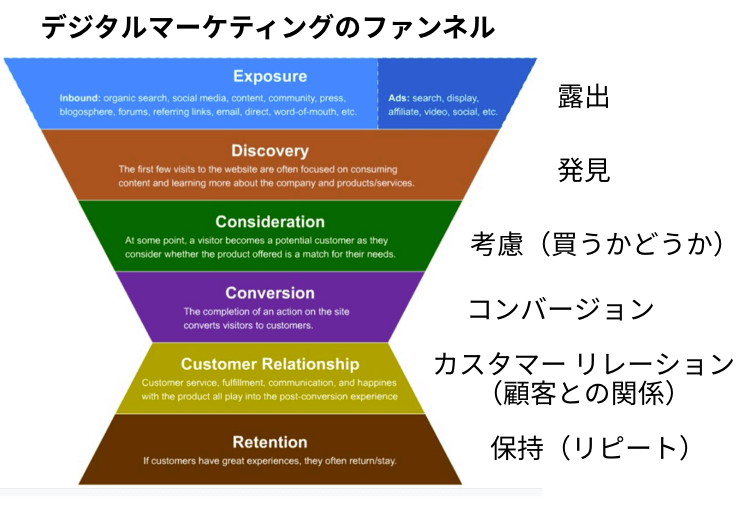
2012年は、このファンネルのなかで、自分のサイトのコンバージョンに至るまでのプロセスとコンバージョン率だけを気にかけていればよかった。
現在は、初回訪問の後の反動を恐れることなく、Exposure(露出)と Discovery(発見)の段階からユーザーに自発的に選んでもらうことができる。
昔は、たとえば高額な値段を提示することで80%のユーザーが離脱したとしても、自分たちが本当に望んでいる質の高いユーザーが残っている限りは、まったく問題なかった。
2016年を昔とは違うようにさせたのは何か?
2016年を昔とは違うようにさせたのは、Machine Learning(マシーン・ラーニング、機械学習)。
初期の段階では、オーガニック検索のランキングアルゴリズムに機械学習を使うことをGoogleは拒否していた。アミット・シンガル(以前のGoogle検索部門のトップ)は機械学習に対して否定的なバイアスを持っていた。
2012年、広告のCTRを予測するために機械学習を使う論文をGoogleは公開した。
2013年、Matt CuttsはPubConで機械学習について語った。
2015年、検索ランキングにAIを使うRankBrainをGoogleはついに明らかにした。
Googleのアルゴリズムの多くを機械学習が引き受けるようになるにつれて、ランキングの基盤は変化する。
機械学習がどうやって画像を識別し分類するかの仕組みをGoogleは公開している。Googleフォトは写真に写っている世界中の場所を認識できるようになっている。これは、完全に機械学習によるもの。
機械学習は検索で次のように働いていると思われる
機械学習では、考えられるランキング要因(PageRankやTF*IDF、トピックモデリング、QDF、クリックなど)とトレーニングデータ(良い検索結果と悪い検索結果)による学習プロセスを経て、最も適合したアルゴリズムを作り上げる。
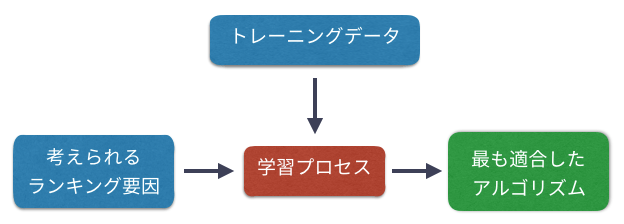
トレーニングデータとは?
トレーニングデータとは、ユーザーが満足する検索結果と満足しない検索結果のデータ。
良い検索結果の例
- 検索者が離脱することがめったにない
- 検索者が検索結果にすぐに戻ってくることがめったにない
- 別のクエリで検索し直すことがめったにない
- 2ページ目に行くことがめったにない
悪い検索結果の例
- 検索者が頻繁に離脱する
- ほかの結果をクリックする
- クリックして訪問したページに長い時間滞在してから検索結果に戻ってくることが稀
- 別の検索クエリを試す
Deep Learning(ディープラーニング)はさらに進んでいる
ディープラーニングを使うと、たとえばネコが何なのかをシステムに教える必要がない、コンピュータは指導されることなく、自分自身で学ぶ。
アルゴリズムを作るアルゴリズムになっている
ディープラーニングにおいては、人間は介在しない。利用できる可能性があるランキング要因を人間が決める必要はない。コンピュータが自分で決定する。
昨年(2015年)、機械学習をベースにしたRankBrainの利用をGoogleはついに明らかにした。RankBrainは間違いなく重要。3番目に重要なシグナルと言われる。GoogleはRankBrainが何を使っているかを確実には理解していないが、RankBrainによる結果を利用している。正しい結果が出ていれば問題ないと考えている。
Googleだけではなく、FacebookやTwitter、Instagramも人工知能を使うようになっている。人工知能でユーザーエンゲージメントが高いコンテンツを判断し、それを露出するようにしている。
エンゲージメントが、ウェブの普遍的な品質指標になりつつある
Google検索のオートコンプリートのサジェストキーワードは、そのクエリでのエンゲージメントに基づいている。Chromeのオートコンプリートも自分やほかのユーザーのエンゲージメントに基いている。Google マップ(パック結果)は、検索ボリュームやルート(経路案内)などのエンゲージメントに基いている。
ソーシャルネットワークのトレンドコンテンツやオススメフォローもエンゲージメントに基いている。
Gmailの重要ラベルもユーザーエンゲージメントに基いている。
露出を決定するエンゲージメントのレピュテーションをサイト・ブランドは獲得しなければならない。
エンゲージメントのレピュテーションとは、「投稿やコンテンツ、ランキングの質」を「クリックやいいね、シェアなどユーザーの反応」で割ったもの。
訪問者が戻るボタンをクリックするたびに、レピュテーションが奪われていく。
戻るボタンに応戦するには?
1. 訪問者の意図を理解し、それに応える
「自分の顧客はだれか?」というペルソナを問うだけでは不十分。検索ユーザーのニーズをすべて理解し、可能な限り多くの解を提供する。顕在・潜在の両方のニーズにアプローチしなければならない。
オートコンプリートや関連検索が調査の役に立つ。
もし、購入しないであろう検索者に対して競合が価値を提供しているのに、あなたが提供していないとしたら、エンゲージメントの戦いには競合が勝利するだろう。
2. その検索順位での平均的なCTRを上回る
titleタグとmeta description、URLを最適化する。キーワードは少なくても、多くのクリックを獲得する。もし3位で、その順位の平均的なCTRよりも上なら順位アップするかもしれない。
- titleタグは、ユーザーが求めているものにマッチしているか?
- URLはクリックしたくなるようなものか?
- ユーザーはあなたのドメインのこと知っていて、クリックしたいと思うか?
- (スニペットに日付が表示される場合)新しいコンテンツか? ユーザーはもっと新しいコンテンツを欲しがっていないか?
- スニペットは興味をそそり、クリックを誘うか?
- ブランドのドロップダウンを表示できているか?[鈴木注: 下のキャプチャ参照。google.comだけの機能]


ブランド検索(指名検索)やブランド名を含んだ検索は順位をさらに上げるかもしれない。今は特に、ブランド検索の影響力がとても大きくなっている。
競争が激しい、あるクエリでの上位5位は広告費用でも上位5位。相関関係と因果関係は違うが、広告にお金をかけることで認知度が増し、ブランド検索が増えているとも考えられる。
オフラインのCMがどのくらいオンラインに影響しているかは、Googleトレンドで調べられる(広告を打った直後に検索ボリュームがどのくらい伸びているか)。
3. シグナルを最適化する: すべてのチャンネルでノイズの比率を下げる
たとえば、コンテンツは多ければいいというものではない。多くのSEOたちが以前は、とにかくコンテンツの量だけでオーソリティを確立しようとしていた。しかしパンダアップデートが導入され、今はRankBrainが導入され、効果をなくした。
ソーシャルのシェアもシェア数が多ければいいというものではない。シェアされた投稿がどのくらいエンゲージされているか(例: 投稿中のURLがどのくらいクリックされているか)が重要。
Facebookではエンゲージメントが良ければ良いほど、次の投稿が目立つようになる。
順位が高ければいいというものではない。1ページ目に絶えず表示されているブランドであっても、検索結果で、検索者の興味を引き続けることができずネガティブなブランド評価を積み重ねていれば順位が下がり、そのブランドでの1位表示が不可能になるかもしれない。ランキングが高いページが多ければ、さらに、ランキングが高いページが多くなる。
4. マーケティングではユーザー体験を最優先する
マーケッターのためのUXのチェックリスト:
- その分野のほかのだれかが提供できるようなコンテンツではなく、権威があり包括的で、 ほかには存在しないコンテンツ
- スピード、スピード、とにかくスピード
- どのデバイスでも利用しやすく楽しめる体験
- 訪問者がエンゲージし、シェアし、また戻ってきたいと思わせる
- やろうとしていたことを思いとどまらせたり、訪問者をイライラさせるような機能を避ける
5. ファンネルの最上部に無視できないCTAを作る
ファンネルの最上部のコンテンツは、顧客にならないユーザーを除外するためだけに使われるべきではない。
ごく一部の検索ユーザーのためだけに役立つコンテンツで1位を取ろうとするのは失敗のもと。戻るボタンを押させないようにするということは、より幅広いユーザーに役立つようにするということ。
あるいは、検索クエリにもっと緻密にして、コンテンツのターゲットを絞り込む。競争がより激しくなく、検索ボリュームがより少ないクエリをターゲットにして、自分たちが探しているユーザーにリーチしているサイトがある。
どちらの方法であっても、エンゲージメント指標がコンテンツのKPIにならなければならない。セッションあたりのページ数を増やし直帰率を下げることが、リンクビルディングのような役割を果たすかもしれない。
コンテンツの中に設置するCTAをカスタマイズし、テストし、洗練させる。
2016年は、エンゲージに基づくレピュテーションの世界に突入した。コンピュータが我々をジャッジする。我々が持っている力を証明しなければならない。
以上です。
やや難しい内容だったかもしれませんね。
特に重要なポイントは次のようになるでしょうか。
- Googleは機械学習による検索アルゴリズムを利用するようになってきた
- 機械学習では、人間の手を介さずにコンピュータが最適なアルゴリズムを創出する
- 機械学習によるアルゴリズムがウェイトを増せば増すほど、ユーザーエンゲージメントが重要になる
- ユーザーエンゲージメントを高めるために、ユーザーを満足させるコンテンツを提供しなければならない
- 検索結果でのクリック率を高める工夫をする
- 検索結果にすぐに戻ってしまわれるようなサイトにしてはいけない
基調講演のタイトルは、『Fight Back Against Back: How Search Engines & Social Networks’ AI Impacts Marketing』でした。
日本語にすると、『戻るボタンに応戦する: 検索エンジンとソーシャル・ネットワークの人工知能はマーケティングにどのようにインパクトを与えるのか』ですかね。
フィッシュキン氏は、検索結果でのクリックがランキングに影響を与えると強く信じている1人です(幾度となく実験している)。
そのために、検索結果でのクリック率を高めること、と同時にクリックされたもののすぐに検索結果に戻ってしまわれないような体験をユーザーに提供する必要があると主張しているのです。
機械学習を取り入れることで、サイトでのユーザー体験の良し悪しをGoogleは判断できるようになっているともフィッシュキン氏は確信しています。
明日は、モバイルセッションをレポートする予定です。