Google ウェブマスターツールにrobots.txtを作成する機能が追加されました。
Google Webmaster Central Blogでも公式にアナウンスされています。
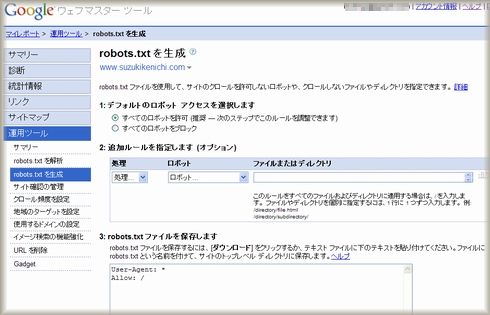
robot.txtとは、検索エンジンのロボット、いわゆるスパイダーもしくはクローラーと呼ばれるプログラムのアクセスを、サイト単位・ディレクトリ単位・ファイル単位で、拒否(許可)するためのテキストファイルです。
※スパイダーとクローラは、厳密には異なるプログラムのようです。
●検索エンジンの5つのプログラム – スパイダーとクローラって別物?
●スパイダーとクローラが別物なわけ
アクセスをブロックする必要がなければ、robots.txtは特に必要ありません。
ウェブマスターツールでは、「すべてのロボットを許可」という指定でrobots.txtを作成できますが、すべてのロボットを許可(Allow)するなら、不要です。
作り方は簡単で、Windowsに付属のメモ帳のようなエディタで作れます。
記述の書式もいたってシンプルです。
robots.txtの書き方については、ネットでたくさん情報が得られるのでここでは省略します。
「robots.txt 書き方」や「robots.txt 書式」で検索してみてください。
※分からなければ、コメントで質問を
慣れてしまえば作るのはどうってことのないものだし、フリーのrobots.txt作成ツールも出回っています。
それでも、Googleの提供するツールの中でrobots.txtを作ることができるのは便利なことです。
Google ウェブマスターツールでのrobots.txt生成機能では、以下の5つのロボットを個別に指定することもできます。
- Googlebot
- Googlebot-Mobile
- Googlebot-Image
- Mediapartners-Google
- Adsbot-Google
Googlebotは通常の「ウェブ検索」のためのロボット、Google-Mobileは「モバイル検索」のためのロボット、Googlebot-Imageは「イメージ検索」のためのロボットです。
Mediapartners-Googleは「AdSense」のためのロボットでページのコンテンツにあった広告を調べるために使われ、Adsbot-Googleは「AdWords」のためのロボットでアドワーズ広告のリンク先ページの品質をチェックするために使われます。
最後の2つは拒否する理由が思いつきませんね。
Mediapartners-Googleをブロックするとどんなアドセンス広告が表示されるんでしょう?
誰か実験してみてくれませんか?(笑)
Adsbot-Googleをブロックすると、ランディングページのクオリティチェックができないのでキーワードの入札価格が高くなるんでしょうか?
こちらも恐くて実験しようとは思いません。w
ちなみに、他の検索エンジンのロボットの名前はどうなっているかというと、
ヤフーは「Slurp(スラープ)」、MSN Live Searchは「MSNbot(エムエスエヌ ボット)」です。
これらはご存知でしょう。
アメリカではGoogle、Yahoo!、MSN Live Searchに続く第4のサーチエンジンのAsk.com(日本ではAsk.jp)は「Teoma(テオマ)」です。
過去のウェブページを保存するWayback MachineのInternet Archiveのロボットは、「ia_archiver(アイエー・アーカイバー)」です。
Robot(ロボット)・Spider(スパイダー)・Crawler(クローラー)・Browser(ブラウザ)をまとめて、User-Agent(ユーザー・エージェント)とひっくるめることもあります。
User-Agentの一覧は、こちらで確認できます。
⇒ User-Agents.org
※公式のサイトというわけではなさそうです。
特定のクローラからのアクセスを拒否(許可)したいというときには、参照してください。
ただし、すべてのクローラがrobots.txtにお行儀よく素直に従うというわけでもないのでご注意を。