[レベル:上級]
今日は、X-Robots-Tagの使い方・書き方について説明します。
新しい情報でもなんでもないのですが、調べごとをしていてたまたまX-Robots-Tagに遭遇して、きちんと記事にしていなかったことに気付き忘備録の意味も兼ねて書いておくことにします。
X-Robots-Tagとは、クローラの動きを制御するときに用いるrobots meta タグを、HTMLドキュメントではないコンテンツのHTTPヘッダーに含めるために使う仕組みです。
たとえば、ウェブページを検索結果に表示させたくないときは、noindex robots meta タグを使います。
しかしXMLサイトマップやPDFドキュメントにはmetaタグはありません。
したがってnoindex robots meta タグを記述するとができません。
こんなときに使うのが、X-Robots-Tagです。
XMLサイトマップを検索結果に表示させたくなければ(たまに表示されるときがある)、Apacheウェブサーバーなら次のように.htaccessに記述します。
<Files sitemap.xml>
Header set X-Robots-Tag "noindex"
</Files>
※XMLサイトマップを「sitemap.xml」という名前で保存している場合なので、ファイル名は環境に合わせて変更する。
サイト内のすべてのPDFドキュメントを検索結果に出したくなければ、次のように記述します。
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>
画像ファイルを検索結果に出したくなければ、次のように記述します。
<Files ~ "\.(jpe?g|gif|png)$">
Header set X-Robots-Tag "noindex"
</Files>
X-Robots-Tagは、noindex robots meta タグに限らず、すべてのrobots meta タグに対応する使用が可能です。
Googleは、PowerPointファイルをインデックスし、中にあるハイパーリンクもたどります。
PowerPointファイルをインデックスもさせない、書かれているリンクもたどらせない、さらにキャッシュも許さないという場合には次のように記述します。
<Files hidden.ppt>
Header set X-Robots-Tag "noindex,nofollow,noarchive"
</Files>
設定した後は、HTTPヘッダーを調べるツールで(Fetch as Googlebotでも大丈夫と思う)きちんとX-Robots-Tagが送信されているか確認しておきましょう。
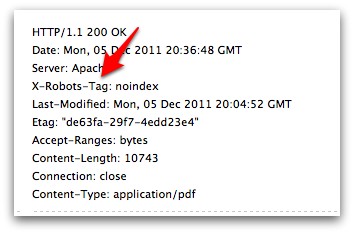
注意点として、X-Robots-Tagで指定したコンテンツをrobots.txtでブロックしてはいけない、という点があります。
robots.txtでブロックしてしまうと、そのコンテンツをクローラは取得しようとしないのでHTTPヘッダーを送ることができません。
検索エンジンに中身を見られることはありませんが、リンクがたくさん張られているときなど状況によっては検索結果にURLだけが表示されることがあります。
X-Robots-Tagは、上級者向けのトピックなので理解できなくても困ることはないと思います。
でも知っておけば、使う場面が出てきたときに思い出して役に立つことがあるでしょう。