[レベル: 初級]
robots.txt でクロールがブロックされているページが Google の検索結果に表示されたときは、その理由の説明がスニペットに掲載されます。
この説明文を Google は変更しました。
このページの情報はありません。
以前は「この結果の説明は、このサイトの robots.txt により表示されません」という説明文でした(2012年8月にこの説明文を導入)。
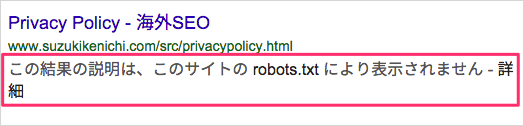
現在は「このページの情報はありません。」に変わっています。
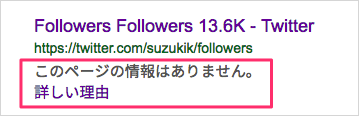
詳細理由を説明するリンク先のヘルプ記事も変更されています。
以前は、robots.txt に関するヘルプ記事でした。
現在は、この説明文の理由を解説するための専用のヘルプ記事を指しています。
検索結果の表示は robots.txt では防げない、noindex との併用は無意味
説明文の変更は些細なことです。
ですが、いい機会なのでついでに検索結果への掲載を robots.txt で防ごうとする設定の落とし穴を復習しておきましょう。
検索結果の表示は robots.txt では防げない
robots.txt で特定の URL のクロールを拒否しても、その URL が検索結果に出ないようにすることには必ずしも役立ちません。
robots.txt でクロール拒否した URL が検索結果に表示されることは普通にあります。
詳しい理由は、こちらの記事を参照してください(8年以上前の記事ですが今でも当てはまります)。
robots.txt と noindex の併用は無意味
検索結果から非表示にするために最も手軽に利用できる手段は noindex robots meta タグです。
ところが、念には念を入れてなのか、noindex タグを記述したページを robots.txt でブロックするサイト管理者がいます。
これはまったく無意味です。
無意味どころか意図したとおりに機能しなくなります。
robots.txt が noindex の認識を妨げてしまい、出したくない URL が検索結果に出てきてしまいます。
詳しい理由は、こちら記事を参照してください。
robots.txt と noindex の併用で墓穴をほった事件が最近ありましたね。😅
この事件を知ったせいかどうかはわかりませんが、robots.txt と noindex の併用について Google の金谷さんも最近注意を促しました。
一度インデックスしたコンテンツを検索結果から削除すべく noindex を追加する場合は、robots.txt でページをブロックしないでください。詳しい情報は、ぜひ Google のヘルプ記事をご覧ください!
ヘルプ記事「noindex を使用して検索インデックス登録をブロックする」https://t.co/FHk4Yh622x
— 金谷 武明 Takeaki Kanaya (@jumpingknee) 2017年11月28日
ということで、「このページの情報はありません。」のスニペットが意図せずに表示されることがないように、robots.txt の使い方にはくれぐれもお気を付けください。