[対象: 上級]
SemTechBiz 2014 カンファレンスでのSEOに関係するセッションを2つレポートしました。
この記事では、SEOよりももっと大きな枠でのセマンティックのセッションをレポートします。
GoogleのRamanathan V. Guha(ラマナサン・V・グーハ)氏による、schema.orgの成り立ちと現状、これからについての基調講演になります。
グーハ氏は、立ち上げ時から大きく関わっているschema.orgの中心人物の1人です。

ではいってみましょう。
構造化データの誕生
18年前に構造化データへの取り組みが始まった。
目的は、「人間のためのウェブ」から「コンピュータと人間のためのウェブ」を実現すること。
たとえば「チャック・ノリス」が俳優で、オクラホマで生まれたということをコンピュータに理解させる。

そのために、コンピュータが理解する共通のボキャブラリとシンタックス、データモデルの策定が必要だった。
RDFやOWL、microformatsなどさまざまな仕様が登場した。
しかし普及しなかった ―― 採用したサイトは1,000以下。ボキャブラリが少ない。実装するメリットを打ち出せなかった。
普及の始まり
2007年に普及が始まった。
Yahoo!のSearch Monkey、Googleのリッチスニペット、FacebookのOpen Graph。
しかし問題も残っており、十分に普及したとはいえなかった。
2010年の状況
選択できる構造化データの仕様が多すぎる。
実装に際してのミスが多い。
結果として、普及率はまだまだ低くとどまったまま。
schema.orgの誕生
2011年にschema.orgを立ち上げた。
すべての検索エンジンが理解できる1つのボキャブラリの確立を目的にした。
ウェブマスターが実装しやすくする。
唯一のボキャブラリではなく、ボキャブラリのなかの1つ ―― ウェブマスターたちは他のボキャブラリと併用が可能。
現在のschema.orgの導入状況
120億のページを調査した。
- 500万のドメイン ―― 全体の6%
- 150億のEntities(エンティティ)
- 650億のTriples(トリプル)
- 25億以上のページがschema.orgを設定 ―― 全体の21%
普及は伸び続けている。
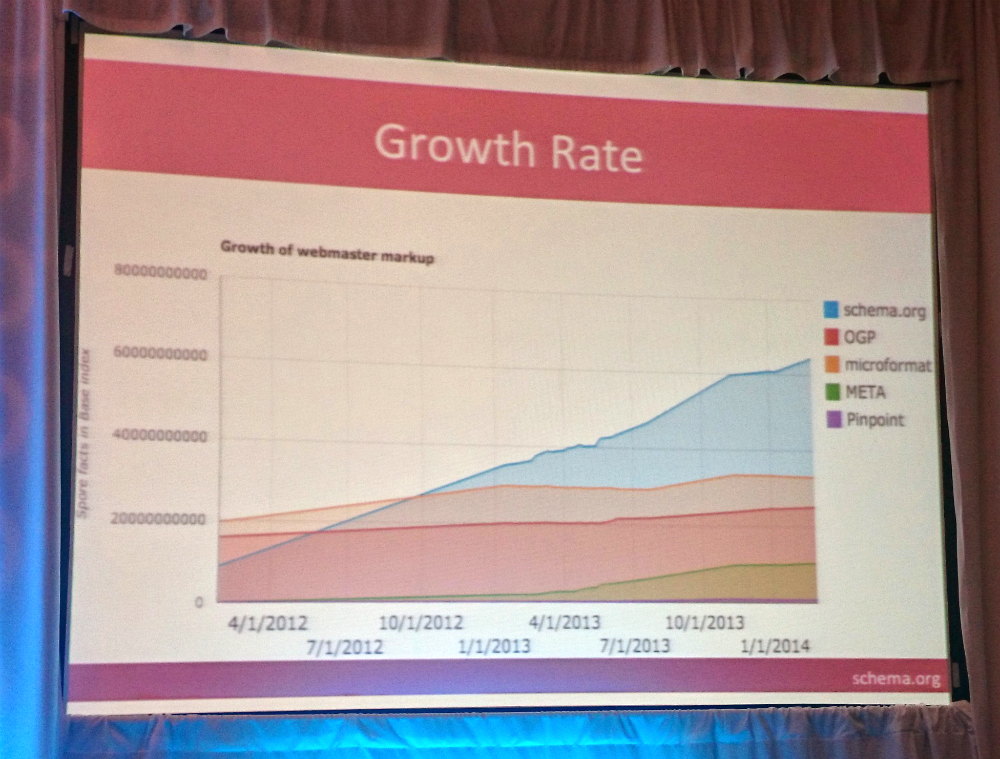
青がschema.org
New York TimesやIMDB、eBay、Yelpなどさまざまなジャンルで多くの大手サイトがschema.orgを導入している(ただしAmazonは未導入)。
schema.orgが普及した理由
- シンプル、しかし複雑なこともできる
- シンタックスとして使いやすいMicrodataを採用 ―― RFDaやJSON-LDも現在は利用可能
- 難解なセマンティックの知識がなくても使える
- 既定のものをコピーして必要に応じて編集できる
- 必要なボキャブラリだけを使えばいい
schema.orgの拡張性
シンプルにスタートした ―― スタート時のカテゴリは約100。
利用者のフィードバックを受けて拡大してきた。
あらゆる領域で利用可能。
採用した後に複雑なことも付け足せる。
現在は1,200以上のボキャブラリが登録されている。
なかったものを後から追加できる。
他との協調
W3Cと協調して取り組んできた。
コミュニティと親密にやりとりした。
他のボキャブラリを取り入れてきた。
DrupalやWordPress、YouTubeなどのプラットフォームと連携している。
schema.orgの最近の出来事
- Actionボキャブラリの追加 ―― 「音楽を聴く」や「料理する」、「予約する」といったアクションを定義できる。
- Roleボキャブラリの追加 ―― たとえば、「ジョー・モンタナは、1979年から1992年までサンフランシスコ49ersでクォーターバックとしてプレイした」のようにその期間と役割を表現できる。
そのほか、TVやラジオ、漫画、Q&A、予約、スポーツなどのボキャブラリを追加した。
さらに拡大を続けている ―― 800以上のプロパティ、600以上のクラス。

schema.orgのこれから
期待以上にschema.orgはうまくいっている。
だがこれが最終ではない。
schema.orgを利用した次世代のアプリケーションをどんどん開発していく。
最初のアプリケーションは検索結果のリッチスニペットだった。
検索以外のアプリケーションも登場する。
新しいアプリケーション
- ナレッジグラフのレビュー/コンサート情報 ―― ナレッジグラフのデータとschema.orgのデータを統合する
- Google Now ―― ユーザープロファイル(GmailやGoogleカレンダーなど)と構造化データのフィードを結びつける
- PinterstのRich Pins ―― Google以外のYahoo!、Bing、Yandexといった他の検索エンジンはもちろんのこと、それ以外もschema.orgを利用している
- OpenTable ―― 1.サイトで予約 => 2. 確認メール => 3. Android(Google Now)がリマインド
Actions in the boxはOpen Tableに限らずだれでも利用可能
[鈴木補足: OpenTable(オープンテーブル)は、レストランのオンライン予約を扱うウェブサイト。Actions in the box(現在はHighlights in Inbox)というGmail/Inboxがサポートする機能を利用している。] - バーティカル検索 ―― イベントやプログラミングなど特定のテーマに絞った検索ツール
政府の利用
米国政府は退役軍人の求人サイトでschema.orgによって情報を意味づけし、探しやすくしている。
科学的調査データ
米国が実施した膨大な科学的調査データを構造化データによって、コンピュータが読める形に変換する。
臨床分野でトライアル実施した。

まとめ
ウェブの構造化データは今、「ウェブ規模」になっている
schema.orgは牽引力を持ち、発展を続けている
(schema.orgを利用した)本当に面白いアプリケーションはまだ世の中に登場していない
以上です。
「文字」ではなく「そのものが何なのか」をコンピュータが理解するための1つの手段として構造化データという技術が生まれました。
しかし潜在的にさまざまな問題があり、思ったように普及しませんでした。
そこで登場したのがschema.orgです。
統一した仕様のもとに普及を目指しました。
シンプルで使いやすい一方で、拡張性・発展性に優れています。
グーハ氏によれば、schema.orgは想像以上に成功しているとのことでした。
特に大手サイトを中心に、利用は確実に伸びているようです。
検索はもちろんのこと検索以外の分野への利用も増えいてます。
「まだまだこんなもんじゃないよ」とグーハ氏はさらなる成長に自信を伺わせました。
schema.orgの将来を楽しみにさせる基調講演でした。
schema.orgに問題があるとすれば、小さなサイトにどうやって採用を促すかだと僕は考えます。
schema.org(構造化データ)の目に見える魅力的なメリットは、リッチスニペットだけといっても過言ではないかもしれません。
実際に、リッチスニペットを”ニンジン”としてGoogleは構造化データの利用を誘ってきました。
でも、構造化データによるマークアップがランキングに直接的に(良い)影響を与えることはありません。
リソースが限られている状況では、効果を測定しにくいことにはリソースを割きづらいですよね。
とはいえ、検索エンジンとしてはもっともっと構造化データを使ってほしいと望んでいます。
先進的にSEOに取り組んでいくのであれば、schema.orgを積極的に採用していくことは決してムダではないと僕は思います。