Googleは、5月12日に「Searchology 2009」というイベントを開催しました。
Searchologyでは、Googleが最近の取り組みや今後の方針などについて発表します。
日本でもニュース系のサイトやSEM系のブログで言及されているので、すでに何らかの情報を得ている読者さんも多いことでしょう。
この記事では、Searchology 2009について日本ではあまり表面に出てきていないであろうと思われる情報を中心に、お伝えします。
まず目玉となる新機能のひとつは、「検索ツール(英語名:Search Option)」です。
こちらはすでに有名なのでこれ以上は触れません。
検索ツールと同じくらい、大きな新機能といえば「サーチウィキ(英語名:SearchWiki)」です。
こちらもすでに有名なので(悪評で?)、機能説明はしません。
Googleのマリッサ・メイヤー(Marrsa Mayer)検索製品および利便性向上担当副社長によれば、1日の検索の40%は同じユーザーによって繰り返された検索だそうです。
つまり同じ人が同じキーワードで、何度も何度も検索しているということになります。
サーチウィキが役立つ理由のひとつです。
たしかに自分が必ずアクセスするサイトを1位に上げておけば、検索結果を探さなくてすみますね。
(ブックマークに登録しておけばいいと思うかもしれませんが、ブックマークを使ったことがなかったり、機能そのものを知らないユーザーもいるでしょう。また、なんでもかんでもサーチエンジンで検索して、アクセスするユーザーもいます。MSNのホームページからの検索で、Hotmailを探すユーザーがいると聞いたことがあります。同じページにHotmailへのリンクがあるにもかかわらずです。)
サーチウィキには、1日に10万のコメントが登録されているとのことです。
これは驚きです。
日本では目新しさも手伝って、コメントを書き込むユーザーがいることは想像できますが(あるいは、これで検索順位が上がると勘違いしているヒトw)、google.comでは半年前に導入されていますから、活用しているユーザーがいるという証拠になりえます。
また、マリッサ・メイヤー副社長によれば、前回2007年のSearchologyで発表されたユニバーサルーサーチは、現在では1/4の検索結果に登場します。
そのとおりで、画像、ニュース、地図、特に動画がSERPに頻繁に差し込まれていますね。
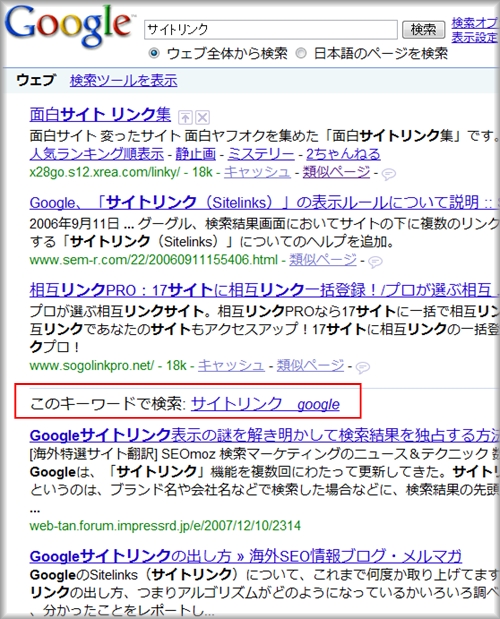
別のスピーカーが、【SEO初心者のEvoブログ】のパシフィカスさんがいち早く発見した「このキーワードで検索 機能」について説明しました。
社内でのコードネーム(開発名称)は「Chameleon(カメレオン)」だったそうです。
Chameleonは、「もしかして:(Did you mean:)」で知られるスペルチェック機能の拡張版で、検索結果ページの中ほどにGoogleが提案した検索結果を表示します。
もう1つのスペルチェック機能の拡張は、「Chameleon + Spelling」で「Spellmeleon(スペルメレオン)」です。
Spellmeleonは、スペルミスしたと思われるキーワードを修正した検索結果を最上部に表示し、その下にもともと入力したキーワードでの検索結果を表示します。
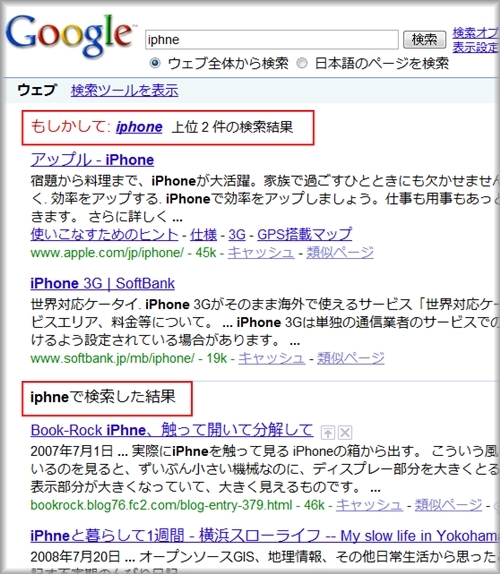
ただこちらの機能は、登場した当初と比べて出現パターンが減っている気がします。
同じキーワードで検索しても、通常の「もしかして:」に戻っています。
アルゴリズムが変わっているみたいですね。
スペルミス修正の機能は、ユーザーにとって便利な機能なだけでなく、スペルミスのキーワードを狙ったウェブスパムの対処にも一役買っているようです。
入力間違いのキーワードでサイトを作っても直されてしまうので、そんな姑息なサイトを作っても労力の無駄になるでしょう。
ちなみにこのスペルチェックの機能を導入することで、ドイツやフランスくらいの規模の国が何もないところからポコッと現れて、人々が検索するくらいGoogleのサーバーにかかる負荷が増加するとのことです。
検索結果に出るウェブページの説明文であるスニペットが拡張しました。
「Rich Snippet(リッチ・スニペット)」と呼び、商品やサービスの「評価を表す星(★)」や「金額」を表示できます。
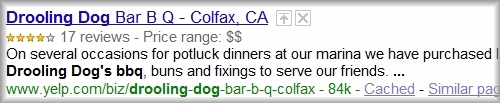
リッチ・スニペットは、信頼されたサイトから徐々に導入されていくようです。
リッチ・スニペットの出し方については、SEMリサーチで渡辺さんが詳しく説明しています。
まだ正式導入ではないものの、「Google Squared(グーグル・スクエアード)」という検索がGoogle Labsで今月後半から試験公開されます。
僕のWeb担当者Forumのコーナーでも概要に触れましたが、ここで、もう少し詳しく説明します。
Google Squaredは、ウェブページではなく、表組み(四角いマス目、つまりSquare)で校正したデータで検索結果を返します。
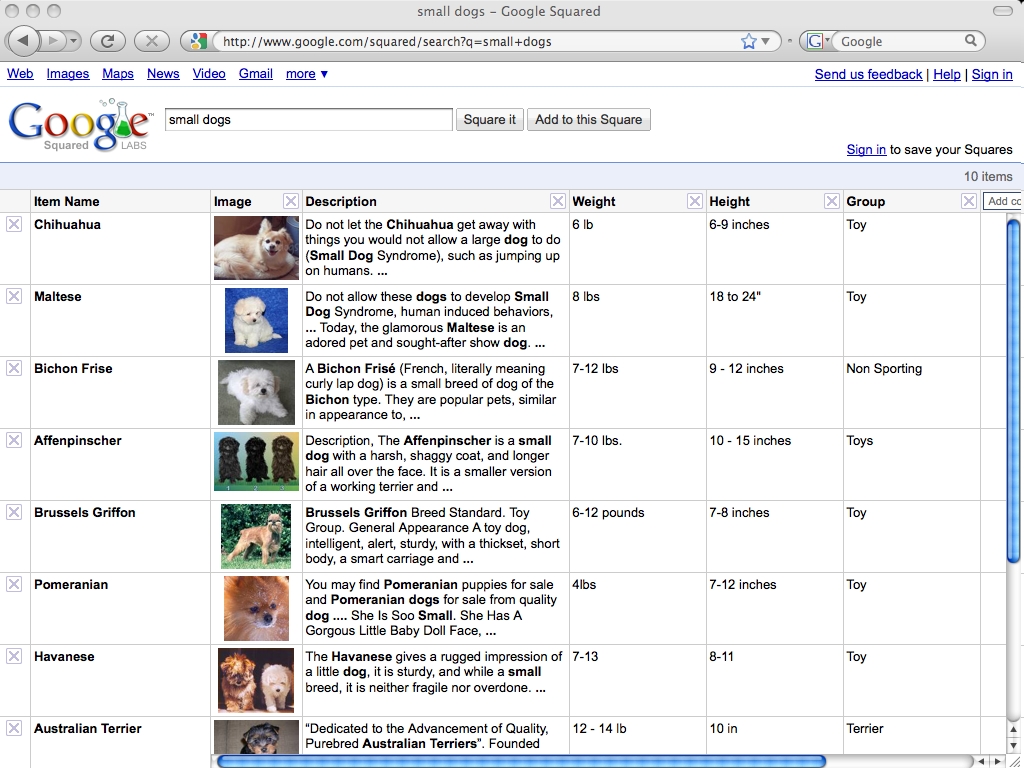
上のキャプチャは「small dogs」を検索したときの結果です。
small dogs(小型犬)に関するウェブページの代わりに、小型犬の情報がExcelシートで作った表のようにまとまっています。
キャプチャで見える情報は、犬の名前、写真、説明、体重、身長、タイプです。
表には自分で項目を追加することもできます。
たとえば、「Shiba ken」を行に追加すれば柴犬に関してのデータも集めてくれます。
また、「countory of origin」を列に追加すれば、それぞれの犬種の原産国を調べてくれます。
※仕組み上、そうなるだろうという推測です。
話はそれますが、「Wolfram Alpha(ウォルフラム・アルファ)」という新しいタイプの検索サービスが、まもなく(予定は5/18)登場します。
※概要はGoogle Squaredと同じくWeb担当者Forumの記事を参照
Wolfram Alphaは、「答えを探し出す」検索エンジンでGoogle Squaredのように、ウェブページの一覧ではなく、実際の種々のデータを収集して加工した上で、検索結果としてまとめてくれます。
Wolfram Alphは事実を導き出してくれる点で、「Facts Engine」という呼称が与えられています。
グーグル・キラーと表現する人もいますが、GoogleはこのGoogle Squaredと先日始めたばかりの統計データ提供機能で、Wolfram Alphaに十分対抗できるのではないでしょうか。
Googleは、モバイル検索についても今後力を入れていく様子で、日本で導入したGoogleモバイルの検索結果における携帯サイトとPCサイトの統合が紹介されました。
以上、Google Searchology 2009についてまとめました。
Googleの進化のスピードは、とどまるところを知らないというのが率直な感想です。
ここで紹介した新機能のいくつかは、1年後には当たり前のように使っていることでしょう。
参照したサイトは以下のとおりです。
- More Search Options and other updates from our Searchology event – Offcial Google Blog
- Google Searchology 2009: Search Options, Google Squared, Rich Snippets – Matt Cutts: Gadgets, Google, and SEO
- What was new at Searchology? – Matt Cutts: Gadgets, Google, and SEO
- Introducing Rich Snippets – Google Webmaster Central Blog
- Screenshots of Google Squared – Google Blogoscoped
※Google SquaredのキャプチャはCreative Commonsに基づき上記のGoogle Blogoscopedの記事から利用(記事執筆者のPhilipp Lenssen氏に確認済み) - Up Close With Google Squared & Some Wolfram Alpha Thoughts – Search Engine Land
- Wolfram Alpha Live Review: The Un-Google – Search Engine Land